Algorithms for prediction
Part 1 of 2: Penalized Linear Regression
Data: Baseball salaries
Code
baseball_population |>
group_by(position) |>
summarize(salary = mean(salary)) |>
mutate(position = fct_reorder(position, -salary)) |>
ggplot(aes(x = position, y = salary)) +
geom_bar(stat = "identity") +
geom_text(
aes(
label = label_currency(
scale = 1e-6, accuracy = .1, suffix = " m"
)(salary)
),
y = 0, color = "white", fontface = "bold",
vjust = -1
) +
scale_y_continuous(
name = "Average Salary",
labels = label_currency(scale = 1e-6, accuracy = 1, suffix = " million")
) +
scale_x_discrete(
name = "Position",
labels = function(x) {
case_when(
x == "C" ~ "C\nCatcher",
x == "RHP" ~ "RHP\nRight-\nHanded\nPitcher",
x == "LHP" ~ "LHP\nLeft-\nHanded\nPitcher",
x == "1B" ~ "1B\nFirst\nBase",
x == "2B" ~ "2B\nSecond\nBase",
x == "SS" ~ "SS\nShortstop",
x == "3B" ~ "3B\nThird\nBase",
x == "OF" ~ "OF\nOutfielder",
x == "DH" ~ "DH\nDesignated\nHitter"
)
}
) +
theme_minimal() +
theme(text = element_text(size = 18)) +
ggtitle("Baseball salaries vary across positions")
Data: Baseball salaries
Code
baseball_population |>
group_by(team) |>
summarize(
salary = mean(salary),
team_past_record = unique(team_past_record)
) |>
ggplot(aes(x = team_past_record, y = salary)) +
geom_point() +
ggrepel::geom_text_repel(
aes(label = team),
size = 2
) +
scale_x_continuous(
name = "Team Past Record: Proportion Wins in 2022"
) +
scale_y_continuous(
name = "Team Average Salary in 2023",
labels = label_currency(
scale = 1e-6,
accuracy = 1,
suffix = " million"
)
) +
theme_minimal() +
theme(text = element_text(size = 18)) +
ggtitle("Baseball salaries vary across teams")
Task: Predict Dodger mean salary

Task: Predict Dodger mean salary

Task: Predict Dodger mean salary

Performance of OLS: Estimator function
Code
tibble(y = many_sample_estimates) |>
# Random jitter for x
mutate(x = runif(n(), -.1, .1)) |>
ggplot(aes(x = x, y = many_sample_estimates)) +
geom_point() +
scale_y_continuous(
name = "Dodger Mean Salary",
labels = label_millions
) +
theme_minimal() +
theme(text = element_text(size = 18)) +
scale_x_continuous(
breaks = NULL, limits = c(-.5,.5),
name = "Each dot is an OLS estimate\nin one sample from the population"
) +
geom_hline(yintercept = true_dodger_mean, linetype = "dashed") +
annotate(geom = "text", x = -.5, y = true_dodger_mean, hjust = 0, vjust = -.5, label = "True mean in\nDodger subpopulation", size = 3)
Model approximation error
Code
population_ols <- lm(salary ~ team_past_record, data = baseball_population)
forplot <- baseball_population |>
mutate(fitted = predict(population_ols)) |>
group_by(team) |>
summarize(
truth = mean(salary),
fitted = unique(fitted),
team_past_record = unique(team_past_record)
)
forplot_dodgers <- forplot |> filter(team == "L.A. Dodgers")
forplot |>
ggplot(aes(x = team_past_record)) +
geom_point(aes(y = truth, color = team == "L.A. Dodgers")) +
geom_line(aes(y = fitted)) +
geom_segment(
data = forplot_dodgers,
aes(
yend = fitted - 3e5, y = truth + 3e5,
),
arrow = arrow(length = unit(.05,"in"), ends = "both"), color = "dodgerblue"
) +
geom_text(
data = forplot_dodgers,
aes(
x = team_past_record + .02,
y = .5 * (fitted + truth),
label = "model\napproximation\nerror"
),
size = 2, color = "dodgerblue", hjust = 0
) +
geom_text(
data = forplot_dodgers,
aes(y = truth, label = "L.A.\nDodgers"),
color = "dodgerblue",
vjust = 1.8, size = 2
) +
scale_color_manual(
values = c("gray","dodgerblue")
) +
scale_y_continuous(
name = "Team Mean Salary in 2023",
labels = label_currency(
scale = 1e-6, accuracy = .1, suffix = " million"
)
) +
scale_x_continuous(limits = c(.3,.8), name = "Team Past Record: Proportion Wins in 2022") +
theme_classic() +
theme(legend.position = "none", text = element_text(size = 18))
OLS with many parameters
Code
# Create many sample estimates with categorical teams
many_sample_estimates_categories <- foreach(
repetition = 1:100, .combine = "c"
) %do% {
# Draw a sample from the population
baseball_sample <- baseball_population |>
group_by(team) |>
slice_sample(n = 5) |>
ungroup()
# Apply the estimator to the sample# Learn a model in the sample
ols <- lm(
salary ~ team,
data = baseball_sample
)
# Predict for our target population
ols_predicted <- dodgers_to_predict |>
mutate(predicted_salary = predict(ols, newdata = dodgers_to_predict))
# Average over the target population
ols_estimate <- ols_predicted |>
summarize(ols_estimate = mean(predicted_salary)) |>
pull(ols_estimate)
# Return the estimate
return(ols_estimate)
}
# Visualize
tibble(x = "OLS linear in\nteam past record", y = many_sample_estimates) |>
bind_rows(
tibble(x = "OLS with categorical\nteam indicators", y = many_sample_estimates_categories)
) |>
ggplot(aes(x = x, y = y)) +
geom_jitter(width = .2, height = 0) +
scale_y_continuous(
name = "Dodger Mean Salary",
labels = label_currency(
scale = 1e-6, accuracy = .1, suffix = " million"
)
) +
theme_minimal() +
theme(text = element_text(size = 18)) +
scale_x_discrete(
name = "Estimator"
) +
ggtitle(NULL, subtitle = "Each dot is an estimate in one sample from the population") +
geom_hline(yintercept = true_dodger_mean, linetype = "dashed") +
annotate(geom = "text", x = .4, y = true_dodger_mean, hjust = 0, vjust = .5, label = "Truth in\npopulation", size = 3)
Regularization
Code
estimates_by_w <- foreach(w_value = seq(0,1,.05), .combine = "rbind") %do% {
tibble(
w = w_value,
estimate = (1 - w) * dodger_sample_mean + w * ols_estimate
)
}
estimates_by_w |>
ggplot(aes(x = w, y = estimate)) +
geom_point() +
geom_line() +
geom_text(
data = estimates_by_w |>
filter(w %in% c(0,1)) |>
mutate(
w = w + c(1,-1) * .13,
hjust = c(0,1),
label = c("Nonparametric Dodger Sample Mean",
"Linear Prediction from OLS")
),
aes(label = label, hjust = hjust)
) +
geom_segment(
data = estimates_by_w |>
filter(w %in% c(0,1)) |>
mutate(x = w + c(1,-1) * .12,
xend = w + c(1,-1) * .04),
aes(x = x, xend = xend),
arrow = arrow(length = unit(.08,"in"))
) +
annotate(
geom = "text", x = .3, y = estimates_by_w$estimate[12],
label = "Partial\nPooling\nEstimates",
vjust = 1
) +
annotate(
geom = "segment",
x = c(.3,.4),
xend = c(.3,.55),
y = estimates_by_w$estimate[c(11,14)],
yend = estimates_by_w$estimate[c(8,14)],
arrow = arrow(length = unit(.08,"in"))
) +
scale_x_continuous("Weight: Amount of Shrinkage Toward Linear Fit") +
scale_y_continuous(
labels = label_currency(
scale = 1e-6, accuracy = .1, suffix = " million"
),
name = "Dodger Mean Salary Estimates",
expand = expansion(mult =.1)
) +
theme_minimal() +
theme(text = element_text(size = 18))
Regularization: How much?
Code
repeated_simulations <- foreach(rep = 1:100, .combine = "rbind") %do% {
a_sample <- baseball_population |>
group_by(team) |>
slice_sample(n = 5) |>
ungroup()
ols_fit <- lm(salary ~ team_past_record, data = a_sample)
ols_estimate <- predict(
ols_fit,
newdata = baseball_population |>
filter(team == "L.A. Dodgers") |>
distinct(team_past_record)
)
nonparametric_estimate <- a_sample |>
filter(team == "L.A. Dodgers") |>
summarize(salary = mean(salary)) |>
pull(salary)
foreach(w_value = seq(0,1,.05), .combine = "rbind") %do% {
tibble(
w = w_value,
estimate = w * ols_estimate + (1 - w) * nonparametric_estimate
)
}
}
aggregated <- repeated_simulations |>
group_by(w) |>
summarize(mse = mean((estimate - true_dodger_mean) ^ 2)) |>
mutate(best = mse == min(mse))
aggregated |>
ggplot(aes(x = w, y = mse, color = best)) +
geom_line() +
geom_point() +
scale_y_continuous(name = "Expected Squared Error\nfor Dodger Mean Salary") +
scale_x_continuous(name = "Weight: Amount of Shrinkage Toward Linear Fit") +
scale_color_manual(values = c("black","dodgerblue")) +
geom_vline(xintercept = c(0,1), linetype = "dashed") +
theme_minimal() +
theme(legend.position = "none", text = element_text(size = 18)) +
annotate(
geom = "text",
x = c(0.02,.98),
y = range(aggregated$mse),
hjust = c(0,1), vjust = c(0,1),
size = 3,
label = c(
"Nonparametric estimator:\nDodger mean salary",
"Model-based estimator:\nOLS linear prediction"
)
) +
annotate(
geom = "text",
x = aggregated$w[aggregated$best],
y = min(aggregated$mse) + .2 * diff(range(aggregated$mse)),
vjust = -.1,
label = "Best-Performing\nEstimator",
size = 3,
color = "dodgerblue"
) +
annotate(
geom = "segment",
x = aggregated$w[aggregated$best],
y = min(aggregated$mse) + .18 * diff(range(aggregated$mse)),
yend = min(aggregated$mse) + .05 * diff(range(aggregated$mse)),
arrow = arrow(length = unit(.08,"in")),
color = "dodgerblue"
)
Multilevel models: Intuition
Code
p <- baseball_sample |>
group_by(team) |>
mutate(nonparametric = mean(salary)) |>
ungroup() |>
mutate(
fitted = predict(multilevel)
) |>
distinct(team, team_past_record, fitted, nonparametric) |>
ungroup() |>
ggplot(aes(x = team_past_record)) +
geom_point(aes(y = nonparametric)) +
geom_abline(
intercept = fixef(multilevel)[1],
slope = fixef(multilevel)[2],
linetype = "dashed"
) +
geom_segment(
aes(y = nonparametric, yend = fitted),
arrow = arrow(length = unit(.05,"in"))
) +
geom_point(aes(y = nonparametric)) +
theme_minimal() +
theme(text = element_text(size = 18)) +
scale_y_continuous(
name = "Team Mean Salary in 2023",
labels = label_currency(
scale = 1e-6, accuracy = .1, suffix = " million"
)
) +
scale_x_continuous(name = "Team Past Record: Proportion Wins in 2022") +
ggtitle("Multilevel model on a sample of 5 players per team",
subtitle = "Points are nonparametric sample mean estimates.\nArrow ends are multilevel model estimates.\nDashed line is an unregularized fixed effect.")
p
Multilevel models: Intuition
Code
bigger_sample <- baseball_population |>
group_by(team) |>
slice_sample(n = 20) |>
ungroup()
multilevel_big <- lmer(formula(multilevel), data = bigger_sample)
bigger_sample |>
group_by(team) |>
mutate(nonparametric = mean(salary)) |>
ungroup() |>
mutate(
fitted = predict(multilevel_big)
) |>
distinct(team, team_past_record, fitted, nonparametric) |>
ungroup() |>
ggplot(aes(x = team_past_record)) +
geom_point(aes(y = nonparametric)) +
geom_abline(
intercept = fixef(multilevel_big)[1],
slope = fixef(multilevel_big)[2],
linetype = "dashed"
) +
geom_segment(
aes(y = nonparametric, yend = fitted),
arrow = arrow(length = unit(.05,"in"))
) +
geom_point(aes(y = nonparametric)) +
#ggrepel::geom_text_repel(aes(y = fitted, label = team), size = 2) +
theme_minimal() +
theme(text = element_text(size = 18)) +
scale_y_continuous(
name = "Team Mean Salary in 2023",
labels = label_currency(
scale = 1e-6, accuracy = .1, suffix = " million"
),
limits = layer_scales(p)$y$range$range
) +
scale_x_continuous(name = "Team Past Record: Proportion Wins in 2022") +
ggtitle("Multilevel model on a sample of 20 players per team",
subtitle = "Points are nonparametric sample mean estimates.\nArrow ends are multilevel model estimates.\nDashed line is an unregularized fixed effect.")
Multilevel models: Performance
Code
many_sample_estimates_multilevel <- foreach(
repetition = 1:100, .combine = "c"
) %do% {
# Draw a sample from the population
baseball_sample <- baseball_population |>
group_by(team) |>
slice_sample(n = 5) |>
ungroup()
# Apply the estimator to the sample# Learn a model in the sample
multilevel <- lmer(
salary ~ team_past_record + (1 | team),
data = baseball_sample
)
# Predict for our target population
mutilevel_predicted <- dodgers_to_predict |>
mutate(predicted_salary = predict(multilevel, newdata = dodgers_to_predict))
# Average over the target population
mutilevel_estimate <- mutilevel_predicted |>
summarize(mutilevel_estimate = mean(predicted_salary)) |>
pull(mutilevel_estimate)
# Return the estimate
return(mutilevel_estimate)
}
# Visualize
tibble(x = "OLS with\nlinear record", y = many_sample_estimates) |>
bind_rows(
tibble(x = "OLS with\nteam indicators", y = many_sample_estimates_categories)
) |>
bind_rows(
tibble(x = "Multilevel\nmodel", y = many_sample_estimates_multilevel)
) |>
ggplot(aes(x = x, y = y)) +
geom_jitter(width = .2, height = 0) +
scale_y_continuous(
name = "Dodger Mean Salary",
labels = label_currency(
scale = 1e-6, accuracy = .1, suffix = " million"
)
) +
theme_minimal() +
scale_x_discrete(
name = "Estimator"
) +
ggtitle(NULL, subtitle = "Each dot is an estimate in one sample from the population") +
geom_hline(yintercept = true_dodger_mean, linetype = "dashed") +
annotate(geom = "text", x = .4, y = true_dodger_mean, hjust = 0, vjust = .5, label = "Truth in\npopulation", size = 3)
Ridge regression: Estimates
Code
p_ridge <- baseball_sample |>
group_by(team) |>
mutate(nonparametric = mean(salary)) |>
ungroup() |>
mutate(
fitted = predict(
ridge,
s = ridge$lambda[50],
newx = model.matrix(~-1 + team_past_record + team, data = baseball_sample)
)
) |>
distinct(team, team_past_record, fitted, nonparametric) |>
ungroup() |>
ggplot(aes(x = team_past_record)) +
geom_point(aes(y = nonparametric)) +
geom_abline(
intercept = coef(ridge, s = ridge$lambda[20])[1],
slope = coef(ridge, s = ridge$lambda[20])[2],
linetype = "dashed"
) +
geom_segment(
aes(y = nonparametric, yend = fitted),
arrow = arrow(length = unit(.05,"in"))
) +
geom_point(aes(y = nonparametric)) +
#ggrepel::geom_text_repel(aes(y = fitted, label = team), size = 2) +
theme_minimal() +
theme(text = element_text(size = 18)) +
scale_y_continuous(
name = "Team Mean Salary in 2023",
labels = label_currency(
scale = 1e-6, accuracy = .1, suffix = " million"
)
) +
scale_x_continuous(name = "Team Past Record: Proportion Wins in 2022") +
ggtitle("Ridge regression on a sample of 5 players per team",
subtitle = "Points are nonparametric sample mean estimates.\nArrow ends are ridge regression estimates.\nDashed line is the unregularized component of the model.")
p_ridge
Ridge regression: Penalty parameter \(\lambda\) controls shrinkage
Code
fitted <- predict(
ridge,
s = ridge$lambda[c(20,60,80)],
newx = model.matrix(~-1 + team_past_record + team, data = baseball_sample)
)
colnames(fitted) <- c("Large Lambda Value","Medium Lambda Value","Small Lambda Value")
baseball_sample |>
group_by(team) |>
mutate(nonparametric = mean(salary)) |>
ungroup() |>
bind_cols(fitted) |>
select(team, team_past_record, nonparametric, contains("Lambda")) |>
pivot_longer(cols = contains('Lambda')) |>
distinct() |>
mutate(name = fct_rev(name)) |>
ggplot(aes(x = team_past_record)) +
geom_point(aes(y = nonparametric), size = .8) +
geom_segment(
aes(y = nonparametric, yend = value),
arrow = arrow(length = unit(.04,"in"))
) +
facet_wrap(~name) +
#ggrepel::geom_text_repel(aes(y = fitted, label = team), size = 2) +
theme_minimal() +
theme(text = element_text(size = 18)) +
scale_y_continuous(
name = "Team Mean Salary in 2023",
labels = label_currency(
scale = 1e-6, accuracy = .1, suffix = " million"
)
) +
scale_x_continuous(name = "Team Past Record: Proportion Wins in 2022") +
ggtitle("Ridge regression on a sample of 5 players per team",
subtitle = "Points are nonparametric sample mean estimates.\nArrow ends are ridge regression estimates.\nDashed line is the unregularized component of the model.")
Ridge regression: Penalty parameter \(\lambda\) controls shrinkage
Code
fitted <- predict(
ridge,
newx = model.matrix(~-1 + team_past_record + team, data = baseball_sample)
)
dodgers_sample_mean <- baseball_sample |>
filter(team == "L.A. Dodgers") |>
summarize(salary = mean(salary)) |>
pull(salary)
ols_estimate <- predict(
lm(salary ~ team_past_record, data = baseball_sample),
newdata = baseball_sample |> filter(team == "L.A. Dodgers") |> slice_head(n = 1)
)
tibble(estimate = fitted[baseball_sample$team == "L.A. Dodgers",][1,],
lambda = ridge$lambda) |>
ggplot(aes(x = lambda, y = estimate)) +
geom_line() +
scale_y_continuous(
name = "Dodger Mean Salary Estimate",
labels = label_currency(
scale = 1e-6, accuracy = .1, suffix = " million"
),
expand = expansion(mult = .2)
) +
scale_x_continuous(
name = "Ridge Regression Penalty Term",
limits = c(0,1e8)
) +
annotate(
geom = "point", x = 0, y = dodgers_sample_mean
) +
annotate(geom = "segment", x = .85e7, xend = .2e7, y = dodgers_sample_mean,
arrow = arrow(length = unit(.05,"in"))) +
annotate(
geom = "text", x = 1e7, y = dodgers_sample_mean,
label = "Mean salary of 5 sampled Dodgers",
hjust = 0, size = 3
) +
geom_hline(yintercept = ols_estimate, linetype = "dashed") +
annotate(
geom = "text",
x = 0, y = ols_estimate,
label = "Dashed line = Prediction that does not allow any team-specific deviations",
vjust = -.8, size = 3, hjust = 0
) +
theme_minimal() +
theme(text = element_text(size = 18))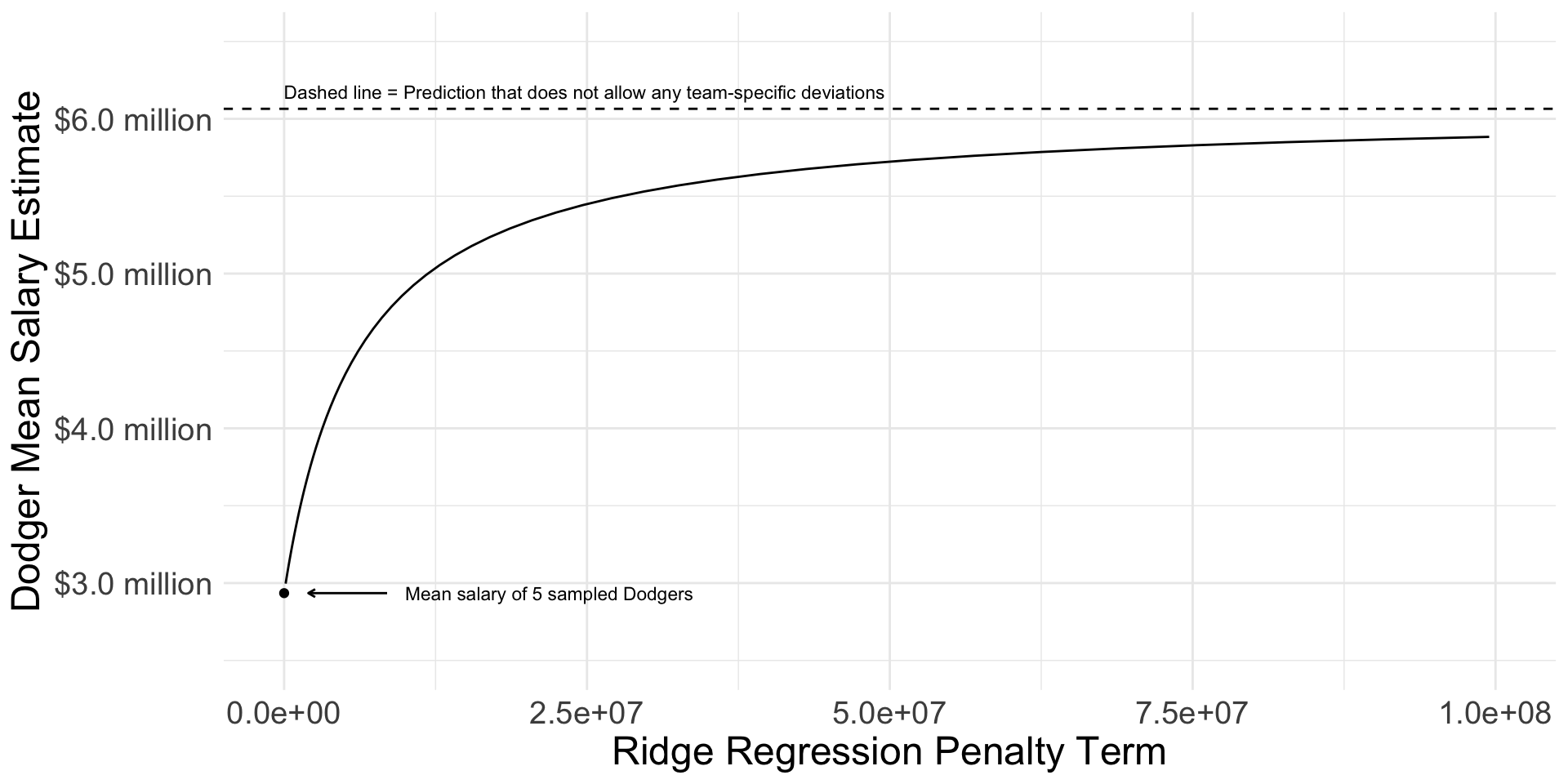
We will discuss how to choose the value of lambda more in two weeks when we discuss data-driven selection of an estimator.
Performance over repeated samples
The ridge regression estimator has intuitive performance across repeated samples: the variance of the estimates decreases as the value of the penalty parameter \(\lambda\) rises. The biase of the estimates also increases as the value of \(\lambda\) increases. The optimal value of \(\lambda\) is a problem-specific question that requires one to balance the tradeoff between bias and variance.
Code
many_sample_estimates_ridge <- foreach(
repetition = 1:100, .combine = "rbind"
) %do% {
# Draw a sample from the population
baseball_sample <- baseball_population |>
group_by(team) |>
slice_sample(n = 5) |>
ungroup()
# Apply the estimator to the sample# Learn a model in the sample
ridge <- glmnet(
x = model.matrix(~ -1 + team_past_record + team, data = baseball_sample),
y = baseball_sample$salary,
penalty.factor = c(0,rep(1,30)),
alpha = 0
)
# Predict for our target population
fitted <- predict(
ridge,
s = ridge$lambda[c(20,60,80)],
newx = model.matrix(~-1 + team_past_record + team, data = baseball_sample)
)
colnames(fitted) <- c("Large Lambda Value","Medium Lambda Value","Small Lambda Value")
as_tibble(
as.matrix(fitted[baseball_sample$team == "L.A. Dodgers",][1,]),
rownames = "estimator"
) |>
rename(estimate = V1)
}
# Visualize
many_sample_estimates_ridge |>
mutate(estimator = fct_rev(estimator)) |>
ggplot(aes(x = estimator, y = estimate)) +
geom_jitter(width = .2, height = 0) +
scale_y_continuous(
name = "Dodger Mean Salary",
labels = label_currency(
scale = 1e-6, accuracy = .1, suffix = " million"
)
) +
theme_minimal() +
scale_x_discrete(
name = "Estimator"
) +
ggtitle(NULL, subtitle = "Each dot is an estimate in one sample from the population") +
geom_hline(yintercept = true_dodger_mean, linetype = "dashed") +
annotate(geom = "text", x = .4, y = true_dodger_mean, hjust = 0, vjust = .5, label = "Truth in\npopulation", size = 3)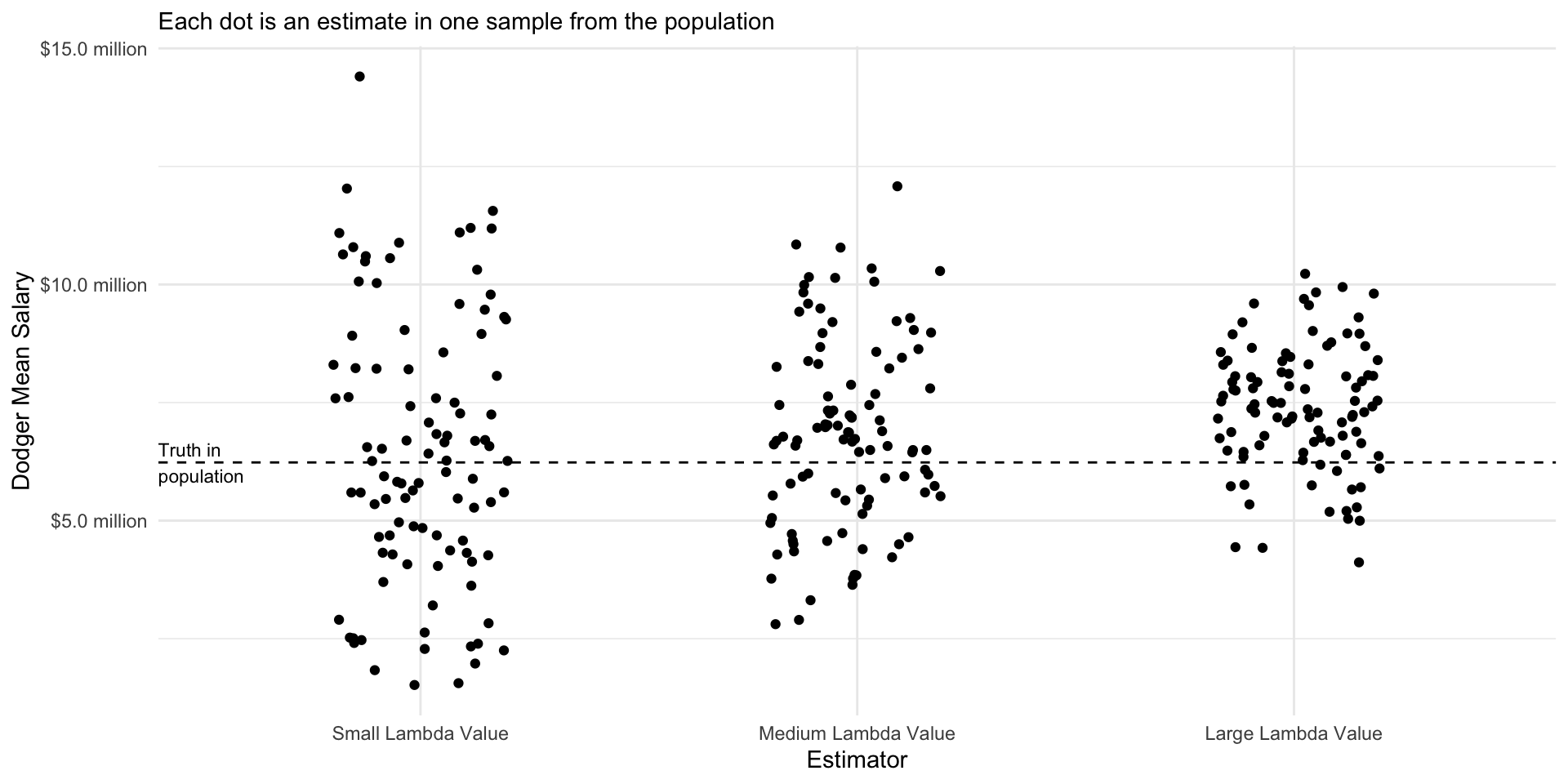
Connections: Multilevel model and ridge regression
Code
p <- both_estimators |>
ggplot(aes(x = yhat_ridge, y = yhat_multilevel, label = team)) +
geom_abline(intercept = 0, slope = 1) +
scale_x_continuous(
name = "Ridge Regression",
labels = label_currency(
scale = 1e-6, accuracy = .1, suffix = " million"
)
) +
scale_y_continuous(
name = "Multilevel Model",,
labels = label_currency(
scale = 1e-6, accuracy = .1, suffix = " million"
)
) +
theme_minimal() +
geom_point(alpha = 0) +
theme(text = element_text(size = 18))
p
Connections: Multilevel model and ridge regression

LASSO estimates
Code
p_lasso <- baseball_sample |>
group_by(team) |>
mutate(nonparametric = mean(salary)) |>
ungroup() |>
mutate(
fitted = predict(
lasso,
s = lasso$lambda[20],
newx = model.matrix(~-1 + team_past_record + team, data = baseball_sample)
)
) |>
distinct(team, team_past_record, fitted, nonparametric) |>
ungroup() |>
ggplot(aes(x = team_past_record)) +
geom_point(aes(y = nonparametric)) +
geom_abline(
intercept = coef(lasso, s = lasso$lambda[20])[1],
slope = coef(lasso, s = lasso$lambda[20])[2],
linetype = "dashed"
) +
geom_segment(
aes(y = nonparametric, yend = fitted),
arrow = arrow(length = unit(.05,"in"))
) +
geom_point(aes(y = nonparametric)) +
#ggrepel::geom_text_repel(aes(y = fitted, label = team), size = 2) +
theme_minimal() +
theme(text = element_text(size = 18)) +
scale_y_continuous(
name = "Team Mean Salary in 2023",
labels = label_currency(
scale = 1e-6, accuracy = .1, suffix = " million"
)
) +
scale_x_continuous(name = "Team Past Record: Proportion Wins in 2022") +
ggtitle("LASSO regression on a sample of 5 players per team",
subtitle = "Points are nonparametric sample mean estimates.\nArrow ends are ridge regression estimates.\nDashed line is the unregularized component of the model.")
p_lasso
LASSO estimates

LASSO estimates
Code
fitted <- predict(
lasso,
newx = model.matrix(~-1 + team_past_record + team, data = baseball_sample)
)
dodgers_sample_mean <- baseball_sample |>
filter(team == "L.A. Dodgers") |>
summarize(salary = mean(salary)) |>
pull(salary)
ols_estimate <- predict(
lm(salary ~ team_past_record, data = baseball_sample),
newdata = baseball_sample |> filter(team == "L.A. Dodgers") |> slice_head(n = 1)
)
tibble(estimate = fitted[baseball_sample$team == "L.A. Dodgers",][1,],
lambda = lasso$lambda) |>
ggplot(aes(x = lambda, y = estimate)) +
geom_line() +
scale_y_continuous(
name = "Dodger Mean Salary Estimate",
labels = label_currency(
scale = 1e-6, accuracy = .1, suffix = " million"
),
expand = expansion(mult = .2)
) +
scale_x_continuous(
name = "LASSO Regression Penalty Term",
limits = c(0,2.5e6)
) +
annotate(
geom = "point", x = 0, y = dodgers_sample_mean
) +
annotate(geom = "segment", x = 2.5e5, xend = 1e5, y = dodgers_sample_mean,
arrow = arrow(length = unit(.05,"in"))) +
annotate(
geom = "text", x = 3e5, y = dodgers_sample_mean,
label = "Mean salary of 5 sampled Dodgers",
hjust = 0, size = 3
) +
geom_hline(yintercept = ols_estimate, linetype = "dashed") +
annotate(
geom = "text",
x = 0, y = ols_estimate,
label = "Dashed line = Prediction that does not allow any team-specific deviations",
vjust = -.8, size = 3, hjust = 0
) +
theme_minimal() +
theme(text = element_text(size = 18))
LASSO: Performance
Code
many_sample_estimates_lasso <- foreach(
repetition = 1:100, .combine = "rbind"
) %do% {
# Draw a sample from the population
baseball_sample <- baseball_population |>
group_by(team) |>
slice_sample(n = 5) |>
ungroup()
# Apply the estimator to the sample# Learn a model in the sample
lasso <- glmnet(
x = model.matrix(~ -1 + team_past_record + team, data = baseball_sample),
y = baseball_sample$salary,
penalty.factor = c(0,rep(1,30)),
alpha = 1
)
# Predict for our target population
fitted <- predict(
lasso,
s = lasso$lambda[c(15,30,45)],
newx = model.matrix(~-1 + team_past_record + team, data = baseball_sample)
)
colnames(fitted) <- c("Large Lambda Value","Medium Lambda Value","Small Lambda Value")
as_tibble(
as.matrix(fitted[baseball_sample$team == "L.A. Dodgers",][1,]),
rownames = "estimator"
) |>
rename(estimate = V1)
}
# Visualize
many_sample_estimates_lasso |>
mutate(estimator = fct_rev(estimator)) |>
ggplot(aes(x = estimator, y = estimate)) +
geom_jitter(width = .2, height = 0) +
scale_y_continuous(
name = "Dodger Mean Salary",
labels = label_currency(
scale = 1e-6, accuracy = .1, suffix = " million"
)
) +
theme_minimal() +
theme(text = element_text(size = 18)) +
scale_x_discrete(
name = "Estimator"
) +
ggtitle(NULL, subtitle = "Each dot is an estimate in one sample from the population") +
geom_hline(yintercept = true_dodger_mean, linetype = "dashed") +
annotate(geom = "text", x = .4, y = true_dodger_mean, hjust = 0, vjust = .5, label = "Truth in\npopulation", size = 3)